





Аналитика и комментарии
Большие данные и искусственный интеллект на службе банку

Сегодня банки ищут возможности своего развития за счет использования различных новых или хорошо забытых старых технологий. Пару лет назад заговорили о широком применении больших данных и машинного обучения в банковской индустрии. По мнению ряда экспертов, использование больших данных и искусственного интеллекта открывает большие перспективы для банков, чему есть конкретные примеры как в мире, так и в России.
Для того чтобы эффективно использовать большие данные, кредитно-финансовая организация должна иметь достаточный уровень зрелости как с позиции бизнеса, так и с точки зрения ИТ. Вкладываться в технологии больших данных стоит только в том случае, если для этого созрела потребность, когда рост количества накопленной информации и средств ее обработки дает качественный прорыв в получаемых знаниях. Big Data – это не мода, необходимость в ней должна «вызреть».
Одновременно с темой больших данных стало актуальным и применение машинного обучения (Machine Learning, ML) и искусственного интеллекта (Arti cial Intelligence, AI), которые получили для своего развития благодатную почву.
Эксперты отмечают, что искусственный интеллект не является чем-то новым для банковской деятельности. Если под AI понимать возможность машин взаимодействовать и научиться выполнять задачи, которые ранее осуществляли люди, то история искусственного интеллекта в банковской отрасли началась еще с середины прошлого века.
Одним из результатов применения искусственного интеллекта является то, что машинное обучение улучшается с течением времени, по мере обработки дополнительных данных, а также достигает лучших результатов.
В настоящее время банки используют технологии анализа больших данных и машинное обучение для решения ряда задач, например, оперативного получения отчетности, выполнения рутинной работы бэк-офиса, оценки кредитоспособности заемщика (скоринга), недопущения проведения сомнительных операций, мошенничества и отмывания денег, а также для персонализации предлагаемых клиентам банковских продуктов.
БОЛЬШИЕ ДАННЫЕ КАК НОВАЯ НЕФТЬ
В конце 2017 года Ассоциация российских банков провела «Открытую дискуссию» на тему «Большие данные и искусственный интеллект: применение в финансовой сфере и перспективы регулирования». Эксперты высказали свои мысли по данной тематике, рассматривая ее под различными углами – математическим, юридическим, с точки зрения реальной практики применения данных технологий.
Ведущий «Открытой дискуссии», президентАРБ,член-корр.РАН,д.ю.н., профессор Гарегин Тосунян высказал следующую мысль: «Сегодня мы слышим, что большие данные – это новая нефть, и все нацелены на ее добычу. Роботы заменяют собой огромное количество людей самых разных профессий. Без данных невозможно построить цифровую экономику. И кто в этом вопросе отстанет, отстанет навсегда. Сегодня мы не будем делать главный акцент на цифровой экономике, но затронем тот аспект, который, наверное, является ее основной частью, – что такое большие данные и в чем смысл их применения в финансовой сфере. Мы поговорим об областях использования искусственного интеллекта в финансовой сфере. Особо хочу отметить, что применение технологий анализа больших данных и искусственного интеллекта в финансовых услугах может и не сопровождаться таким ажиотажем и такой информационной шумихой, как криптовалюты, в частности, но по значимости трудно переоценить их влияние на финансовую область».
В отличие от ситуации с криптовалютами, банки и другие представители финансовой сферы не ждут сегодня специальных разрешений и указаний на работу с этими данными, потому что искусственный интеллект можно использовать в своей текущей деятельности без специальных разрешений. Поэтому сегодня можно слышать о все новых областях применения искусственного интеллекта в финансовых услугах.
До сих пор не сложилось единого понимания, что такое большие данные и кому они принадлежат, подчеркнул глава АРБ. «Например, когда мы собираем кредитные истории, то предполагается, что это уже обработанная специальным образом информация, которая принадлежит бюро кредитных историй, поскольку они торгуют ей. Но значительная часть этих данных – это персональная информация. И здесь уже возникает спорный момент: где начинаются большие данные, которые можно использовать, а где это будет вторжение в личную жизнь. В этой части уже требуется некое регулирование», – резюмировал президент АРБ.
ИНТУИТИВНОЕ ПОНЯТИЕ С ЭМОЦИОНАЛЬНОЙ НАГРУЗКОЙ
Выступая в ходе «Открытой дискуссии» в АРБ, академик РАН, заместитель директора Федерального исследовательского центра «Информатика и управление» РАН Константин Рудаков отметил, что сейчас действительно возник огромный поток данных: «Большие данные сами по себе объективно существуют, и сейчас наблюдается их катастрофический поток».
Большие данные возникают из-за того, что их порождает огромное количество людей, например, в интернете. При этом само понятие «большие данные» плохо формализовано, оно интуитивно. «Для меня как для математика большие данные – это функция от имеющихся ресурсов и сложности задачи, – сказал Константин Рудаков. – Если дать человеку листок бумаги и попросить сложить миллион чисел, для него это будут большие данные. Большие данные – это понятие интуитивное и имеет эмоциональную нагрузку».
Характерная особенность больших данных заключается в том, что сами по себе они сложные (звуки, видео, сигналы). Но при этом нужны они для того, чтобы принимать простые разумные решения на уровне «да» или «нет».
Большие данные – это прежде всего фундамент для решения каких-то разумных задач. «Если вы не имеете задачи, вообще не надо собирать данные, – уверен Константин Рудаков. – Данных должно быть минимальное достаточное количество. Принципиальное слово здесь «минимальное». Если вы набрали данных, которых достаточно для того, чтобы с надлежащим качеством поддерживать правильное решение, не надо больше собирать. Потому что данные – это еще и сырье, которое довольно часто быстро устаревает. В случае с большими данными нужно идти от полезной конкретной задачи, которую вы будете решать».
По мнению академика Константина Рудакова, главный вызов, связанный с большими данными и с их регулированием, заключается в том, что не они являются сами по себе ценностью, это лишь предпосылка для ее создания. «Без данных, конечно, нельзя, – говорит он. – Но защищать и охранять надо не сами по себе данные, а способы их обработки, ту «вытяжку», которую вы умеете из них получать».
Накопить данные сегодня не сложно, они нередко находятся в открытом доступе (их можно скачать из интернета, украсть, подслушать, подсмотреть и т.д.), но ценным будет то, что человек сумеет сделать с ними, какую выгоду для себя извлечь.
ТЕХНОЛОГИЯ ДОЛЖНА РАЗВИВАТЬСЯ, НЕ НУЖНО ЕЙ ВРЕДИТЬ
Говоря о больших данных и искусственном интеллекте, полезно обратить внимание на несколько обстоятельств, считает доктор физико-математических наук, руководитель лаборатории Федерального исследовательского центра «Информатика и управление» РАН Михаил Забежайло. Во-первых, когда идет работа с этими данными, зачастую мы имеем жесткие ограничения по времени, которое выделяется для анализа информации и принятия решений. Получается, что очень много данных и очень мало времени. В такой ситуации вполне естественно обратиться к помощи компьютерных технологий и попытаться перенести на компьютер часть тех приемов, практик, методик, которыми пользуется эксперт в решении своих задач. Таким образом, большие данные и искусственный интеллект, понимаемый как технология компьютерной обработки и интеллектуального анализа данных, оказываются взаимосвязанными.
Второе соображение, на которое эксперт обратил внимание в ходе «Открытой дискуссии», состоит в следующем: «Иногда кажется, что большие данные есть, но они как бы не с нами. Тем не менее в финансовой сфере легко привести примеры, связанные с клиентскими данными. Например, есть Ситибанк, в котором существует проблема – хранить выписки по карточным счетам. Эти данные очень быстро растут, и с ними очень сложно работать. Для того чтобы переложить способы, которыми эксперт обрабатывает их, на компьютер, должны быть использованы хитрые технологии. При этом отвечать за конечный результат будет человек, принимающий решение».
Третий аспект проблемы заключается в том, что необходимо регулирование этой сферы. «Мы не раз слышали мысли о том, что грядет нашествие роботов, искусственный интеллект всех погубит и т.д. С точки зрения профессионалов здесь есть некое лукавство, – считает Михаил Забежайло. – Искусственный интеллект представляет собой определенное устройство, которое программирует человек. Если он заранее ограничит эти программы, которые будут закладываться в устройство, условиями, что они должны быть полностью понятны и прозрачны пользователю, что «черный ящик» недопустим, что они будут только помощниками человека и своего рода усилителями его интеллектуальных возможностей, то ряд проблем в этой области уничтожится на корню».
Эксперт сделал вывод о том, что проблематика регулирования в этой области действительно актуальна, потому что в этой плоскости лежат вопросы ответственности за принимаемые решения, здесь есть деликатные аспекты, которыми нужно заниматься, хотя бы исходя из принципа «не навреди». «Технология должна развиваться, давайте ей не будем вредить».
С ТОЧКИ ЗРЕНИЯ ЮРИСТОВ-ЦИНИКОВ
Доктор юридических наук, президент IP CLUB, профессор Университета им. О.Е. Кутафина (МГЮА) Марина Рожкова в ходе «Открытой дискуссии» представила свой, юридический, взгляд на само понятие «большие данные» и на проблему необходимости их регулирования.
«Мы, юристы, – циники, и вопросы математики начинают нас интересовать только применительно к получению каких-то материальных благ, – иронично заметила эксперт. – На сегодняшний день большие данные воспринимаются не только как большой объем информации, но и как способы и технологии обработки и хранения сведений. Мы уходим от понимания данных как объекта к способам обработки и хранения, именно они представляют серьезный интерес».
Марина Рожкова обратила внимание на то, что сегодня под данными, как правило, понимаются сырые данные, исходный материал, на основе которого строятся методы и технологии, позволяющие достичь определенного результата. Она привела пример из банковской сферы.
Не так давно Сбербанк объявил о своем желании, начиная с 2018 года, начать программу использования персональных данных из соцсетей. На самом деле у них этот процесс идет и сейчас, но в настоящее время это пилотный проект, в котором применяются не все данные. С 2018 года предполагается использование не только кредитного скоринга, который, как известно, является анализом кредитоспособности людей, в котором учитываются какие-то социальные факторы, например, брак, наличие детей, образование и прочее, но будет приниматься во внимание и психологический портрет пользователя, позволяющий в совокупности с кредитным скорингом оценивать кредитоспособность будущего заемщика. Получается, что абсолютно вся информация, которую пользователи излагают в соцсетях, будет учитываться при составлении портрета получателя кредита. На этом основании будет делаться вывод, является ли этот заемщик кредитоспособным, вернет ли он кредит.
«Когда мы говорим о больших данных, мы имеем в виду прежде всего сырые данные, которые собираются из соцсетей, – подчеркнула Марина Рожкова. – Это картина мира, которая раскладывается по полочкам на основании определенного алгоритма, т.е. для того, чтобы получить какой-то результат, нужен соответствующий алгоритм, который задает машина. И на его основании из всей базы данных появляется результат, который нам дает коммерческую ценность. Поэтому с точки зрения права наиболее важным является то, как большие данные будут использоваться».
СТАЛО ПОНЯТНО, ЗАЧЕМ СОБИРАЛИ ДАННЫЕ
По мнению заместителя генерального директора SAP СНГ Дмитрия Красюкова, только теперь стала ясна целесообразность сбора такого огромного массива данных. Он объяснил свою мысль следующим образом.
Для того чтобы человеку попасть из точки А в точку Б, изначально требовался один день, затем человек изобрел автомобиль и доехал за пять минут, затем создал много автомобилей, и ему опять потребовался один день. Примерно та же самая история происходит с данными. Их накапливается огромное количество, и появляются такие понятия, как «пробки» в данных. В этой связи было не совсем понятно, что делать с таким огромным массивом информации. Сложилась ситуация, когда многие компании накапливают эти данные, строят дата-центры, большие хранилища. Но при этом не было понятно, зачем они все это делают. Причина во многом заключалась в ограниченности человека и его способностей.
«Сейчас, когда мы подошли к тому, что машинное обучение начинает использоваться более широко, становится понятным, зачем нужна была история с большими данными», – подчеркивает Дмитрий Красюков. При подключении алгоритма машинного обучения эффективность и полезность анализа данных возрастает в разы. Сейчас понятно, зачем последние десять лет многие компании, и банки в том числе, собирали эти данные. Почему возник хайп, связанный с искусственным интеллектом? Ведь тема нейронных сетей, машинного обучения достаточно старая. Потому что появились две конкретные предпосылки. Первая – чтобы машинное обучение стало эффективным, нужно огромное количество данных, и действительно появились данные соцсетей, которые лежат в открытом доступе. Вторая предпосылка – это наличие технологий, способных обрабатывать такие огромные объемы информации. Отсюда и возникает эффективный искусственный интеллект, который ряд отраслей берет себе на вооружение.
Возникает вопрос – какие возможности здесь существуют для банков? В любом бизнесе, и банковский здесь не исключение, есть затратная и доходная части. Основные затраты банка, как правило, связаны с арендой площадей и выплатой заработной платы. При этом даже такие инновационные банки, которые позиционируют себя и развиваются как онлайн-банки без открытия отделений, тем не менее, содержат большие колл-центры, в которых работают тысячи людей, обрабатывающие входящий клиентский поток. Сейчас около 10% обращений обрабатывается ботами, т.е. неким аналогом искусственного интеллекта. Если представить, что этот процент будет расти, то можно прогнозировать сокращение затратных статей для банка. Необходимо помнить, что таким образом нивелируется и так называемый человеческий фактор, ведь люди болеют, увольняются, вновь пришедших необходимо заново обучать и т.д. Искусственный интеллект постепенно накапливает информацию, постоянно обучается и совершенствуется.
«Я уверен, что через короткое время разговор в колл-центре с искусственным интеллектом будет эффективнее, чем с человеком», – подчеркивает Дмитрий Красюков.
Доходная часть банковского бизнеса может быть увеличена за счет дополнительной продажи клиентам своих продуктов и услуг. «Наверное, все мы получали СМС от банков с предложением кредита или иных продуктов. Часто эти СМС не связаны с реальностью, например, у вас в этом банке ипотека, а вам предлагают открыть депозит. Видно, что банки сейчас недостаточно эффективно анализируют информацию о своих клиентах и не совсем понимают, как можно персонализировать свои предложения. Конечно, большие данные, искусственный интеллект во многом сделают их более точными», – считает генеральный директор компании SAP.
НЕОБХОДИМОСТЬ РАЗВИТИЯ ТЕХНОЛОГИЙ ML/AI
В ноябре прошлого года в Москве прошел первый Российский форум по системам искусственного интеллекта – RAIF (The Russian Arti cial Intelligence Forum), организатором которого выступила компания «Инфосистемы Джет».
Выступая на форуме, руководитель по развитию бизнеса IBM в России и СНГ Майкл Вирт констатировал, что за последние пять лет направление AI серьезно выросло и это движение уже не остановить. Спикер подчеркнул, что уже через десять лет машина сможет принимать решения без человека, а также научится перепрограммировать себя.
Для того чтобы это стало возможным, нам нужно сегодня поработать над созданием более мощных устройств обработки данных и процессоров с низким энергопотреблением.
Заместитель председателя комитета Госдумы по информационной политике, информационным технологиям и связи Александр Ющенко подчеркнул необходимость развития технологий ML/AI как для бизнеса, так и для государства в целом: «Государство сегодня заинтересовано в развитии ИТ, в поддержке перспективных молодых специалистов, стартапов и, конечно, российских ИТ-компаний и интеграторов. Мы должны сегодня создать все условия, чтобы наши специалисты приносили максимальный результат. Им в поддержку мы разрабатываем законодательные акты в области новых перспективных технологий. Однако совершенствование данного направления возможно лишь при объединении усилий государства и бизнеса».
РОССИЙСКИЙ РЫНОК ML И AI ВЫРАСТЕТ ДО 28 МЛРД РУБЛЕЙ К 2020 ГОДУ
Согласно результатам исследования «Актуальные тенденции рынка машинного обучения и искусственного интеллекта», проведенного компанией «Инфосистемы Джет» и аналитическим центром TAdviser, объем рынка искусственного интеллекта (AI) и машинного обучения (ML) в России составил в 2017 году около 700 млн рублей и вырастет о 28 млрд рублей к 2020 году. Его драйверами будут финансовый сектор, ретейл и промышленность.
Такой вывод был сделан по итогам опроса представителей 100 компаний, работающих в России, – ИТ-руководителей, глав департаментов цифровых сервисов / цифровой трансформации, влияющих на принятие решений в области ИТ. Для анализа мировой ситуации использовались данные различных аналитических агентств (IDC, Gartner, Markets and Markets и пр.), консалтинговых компаний и вендоров (PwC, Teradata, SAP и пр.). Исследование проводилось в рамках подготовки к форуму по системам искусственного интеллекта RAIF 2017.
В мире количество проектов в области AI и ML за последние годы выросло в разы. Если в 2015 году глобально анонсировались только 17 проектов, выполненных крупными компаниями, то за первую половину 2017 года – уже 74 проекта. Всего в 2015–2017 годах было зафиксировано 162 таких проекта в 28 странах и 20 отраслях. В 85% случаев речь идет о реализованных проектах, в 15% – о планах или тестовых внедрениях по всем отраслям, за исключением госструктур, где доля тестовых внедрений и анонсов оценивается в 60%. Основная доля заказчиков таких инициатив – крупный бизнес (85%).
США лидирует по количеству проектов AI/ML. Следом идет Великобритания, где эти решения часто используют в крупных инвестиционных банках, а также обслуживающая эту группу заказчиков Индия.
Отечественный сегмент искусственного интеллекта и машинного обучения пока находится на начальной стадии формирования и значительно уступает в объемах крупному AI-рынку США. До недавнего времени практически отсутствовала наглядная демонстрация связи технологий с существующими бизнес-процессами и возможностью их улучшения. В то же время эффективные внедрения часто остаются закрытыми, ведь компании-инноваторы видят в результатах таких проектов источники дополнительного конкурентного преимущества и не спешат ими делиться, говорится в исследовании.Кроме того, некоторые руководители российских компаний отмечают, что бизнес на сегодняшнем уровне автоматизации в среднем пока не готов к использованию таких инструментов. Существенный барьер для развития бизнес-ориентированного AI в России представляют вычислительные мощности. Для активизации проектов необходимо обеспечить соответствующее развитие высокопроизводительной инфраструктуры.
Тем не менее, к настоящему моменту в России уже есть примеры внедрения ML, которые доказывают эффективность применения этих технологий и пользу для бизнеса, отмечают авторы исследования. Так, в ретейле был отмечен рост конверсии до 15% при использовании товарных рекомендаций на базе машинного обучения, при этом количество ручных операций может сократиться до 50 раз. В нескольких опрошенных банках из топ-5 считают, что через 5 лет около 80% всех решений будут приниматься с помощью искусственного интеллекта, и прогнозируют, что отрасль начнет активно переходить на безлюдные технологии (через 3 года клиенты в 50% случаев будут общаться с ботами). Промышленный сектор замыкает тройку лидеров по внедрению AI, однако процент проникновения технологии в компании из этой отрасли пока находится на низком уровне.
Большинство опрошенных организаций, применяющих технологии ML, делают это в целях сокращения издержек (72%), а также для повышения качества своих продуктов или услуг (68%) (см. диаграмму 1). Дополнительно рядом респондентов было отмечено, что инструментарий часто используется ими для решения вопросов, связанных с безопасностью. Более половины опрошенных считают, что AI может обеспечить бизнесу новые экономические выгоды.
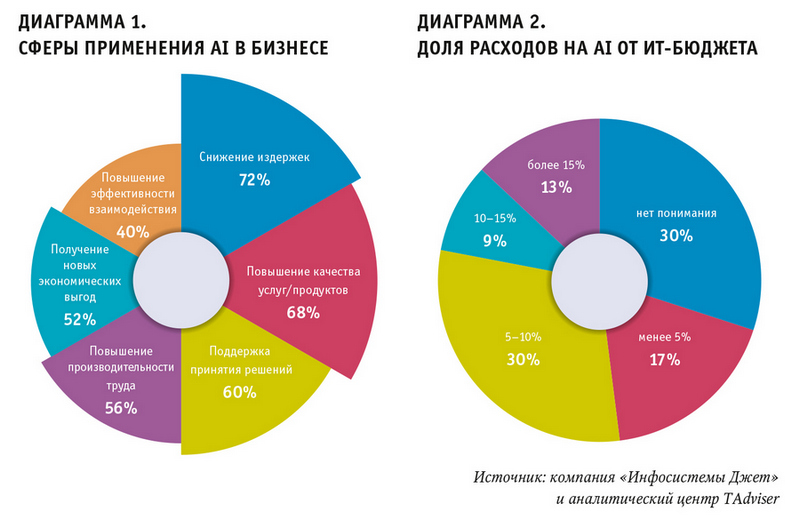
Больше половины респондентов уверены, что их затраты на AI/ML в ближайшие 3–5 лет будут расти, причем примерно треть опрошенных называет цифру в 15–20 % в год (см. диаграмму 2).
Что касается направлений использования AI и ML, то наиболее открыто компании говорят о применении ботов или систем распознавания речи. При этом почти все респонденты подтверждают, что удовлетворены существующим качеством и функционалом решений с учетом стадии их развития. В силу недостаточного уровня развития технологий, а также невысокой степени осведомленности о них большинство респондентов затрудняются указать, каких именно инструментов AI им сегодня не хватает, апеллируя преимущественно к более интеллектуальным поиску и маркетингу. В первую очередь опрошенные компании заинтересованы в сборе актуальной статистики о результатах реализованных ранее внедрений. Она станет основой для принятия решений о новых проектах или инициативах в сфере AI.